
Multilingual Universal Sentence Encoder for Semantic Retrieval
These notes are the first series of my retrospective of multilingual sentence encoders. Yes, it's a weird retrospective which starts with a paper of year 2019. I guess it shows how quickly the field is moving.
The notes are on the paper Multilingual Universal Sentence Encoder for Semantic Retrieval by Yinfei Yang, Daniel Cer et al.
Preface
🔲 Existing large language models such as BERT obtain state-of-the-art performance on many natural language understanding tasks. They are pretrained to create contextual word embeddings and sentence embeddings via masked language modelling and next sentence prediction.
🔲 In monolingual settings they are very effective for both word-level and sentence level tasks. Multilingual representations of sentences were not as effective in cross-lingual settings.
Problem
🌎 For multilingual retrieval tasks, we require goood universal sentence encoder. By universal here I mean one that can capture semantics correctly in multiple domains in several languages.
❔ How can we train such a universal encoder? Is there a possibility to make it more lightweight than its predecessors?
What is the solution proposed?
Model
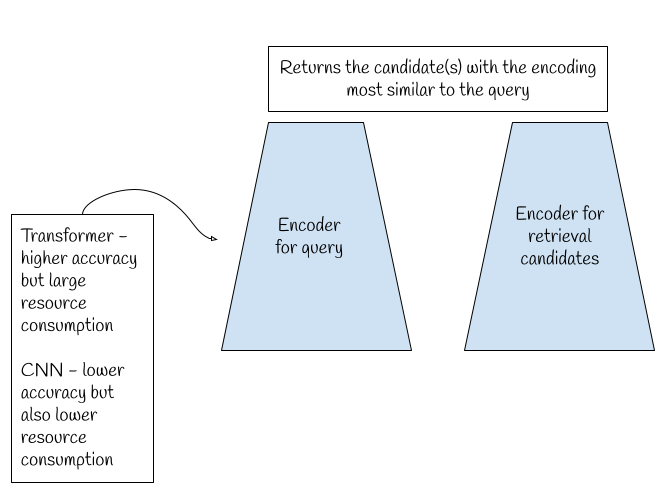
🔬The model is a dual encoder model: one side encodes the query, e.g., the question in the QA task, and the other side encodes all possible candidates, e.g., all possible responses in the QA tasks.
🔬The model computes a similarity metric between the query encoding and the response encodings. The output of the model is the response most similar to the query.
🔬 2 architectures were tried as the encoder: Convolutional Neural Network for parameter efficient network and Transformer encoder for higher accuracy but more resourceful.
Data
For the languages covered, the data includes:
Languages covered:
Results
⭐ Performs well across 16 languages;
⭐ Transfers the knowledge well to unseen retrieval tasks, e.g., sentence classification within SentEval.
⭐ CNN model demonstrates worse performance than Transformer model but is far more resource efficient.
And?
💭 We have a model which works well on 16 languages coming from 7 different language families but it hasn't been in transfer to other languages not covered by training data has not been tested. The set of languages is large but they are mostly high resource laguages.
💭 CNN model is far more resource efficient which makes it a more appealing option for industry, especially when you need to host the model on device.
The notes are on the paper Multilingual Universal Sentence Encoder for Semantic Retrieval by Yinfei Yang, Daniel Cer et al.
Preface
🔲 Existing large language models such as BERT obtain state-of-the-art performance on many natural language understanding tasks. They are pretrained to create contextual word embeddings and sentence embeddings via masked language modelling and next sentence prediction.
🔲 In monolingual settings they are very effective for both word-level and sentence level tasks. Multilingual representations of sentences were not as effective in cross-lingual settings.
Problem
🌎 For multilingual retrieval tasks, we require goood universal sentence encoder. By universal here I mean one that can capture semantics correctly in multiple domains in several languages.
❔ How can we train such a universal encoder? Is there a possibility to make it more lightweight than its predecessors?
What is the solution proposed?
Model
🔬The model is a dual encoder model: one side encodes the query, e.g., the question in the QA task, and the other side encodes all possible candidates, e.g., all possible responses in the QA tasks.
🔬The model computes a similarity metric between the query encoding and the response encodings. The output of the model is the response most similar to the query.
🔬 2 architectures were tried as the encoder: Convolutional Neural Network for parameter efficient network and Transformer encoder for higher accuracy but more resourceful.
Data
For the languages covered, the data includes:
- question answer pairs mined from Reddit, Stack overflow etc.
- translation pairs mined from the Web
- Stanford NLI corpus
Languages covered:
| English (en) | French (fr) | Dutch (nl) | Thai (th) |
|---|---|---|---|
| Arabic (ar) | Italian (it) | Portuguese (pt) | Turkish (tr) |
| German (de) | Japanese (ja) | Polish (pl) | Chinese (zh; zh-tw) |
| Spanish (es) | Korean (ko) | Russian (ru) |
⭐ Performs well across 16 languages;
⭐ Transfers the knowledge well to unseen retrieval tasks, e.g., sentence classification within SentEval.
⭐ CNN model demonstrates worse performance than Transformer model but is far more resource efficient.
And?
💭 We have a model which works well on 16 languages coming from 7 different language families but it hasn't been in transfer to other languages not covered by training data has not been tested. The set of languages is large but they are mostly high resource laguages.
💭 CNN model is far more resource efficient which makes it a more appealing option for industry, especially when you need to host the model on device.